概要
Hi-Cシークエンスは、近接性に基づく相互作用の探査とハイスループットシークエンスを組み合わせることで、染色体の配置を把握するためにデザインされた手法です。相互作用の強度は、染色体上の物理的距離と負の相関があると考えられています。従って、Hi-Cデータは、ドラフトゲノム内のアセンブルされたコンティグのクラスタリング、順序付け、方向付けをガイドし、それらを特定の染色体に割り当てるために使用されます。この技術は、集団ベースの遺伝マップがない場合でも、染色体レベルのゲノムアセンブリを可能にします。Hi-Cはあらゆるゲノムに有効です。(
fig.1)
特長
- シークエンス条件:illumina Novaseq, PE150
- 組織サンプルで受入れ: ホルムアルデヒドでCross-linkし、DNAとタンパク質の相互作用を保存
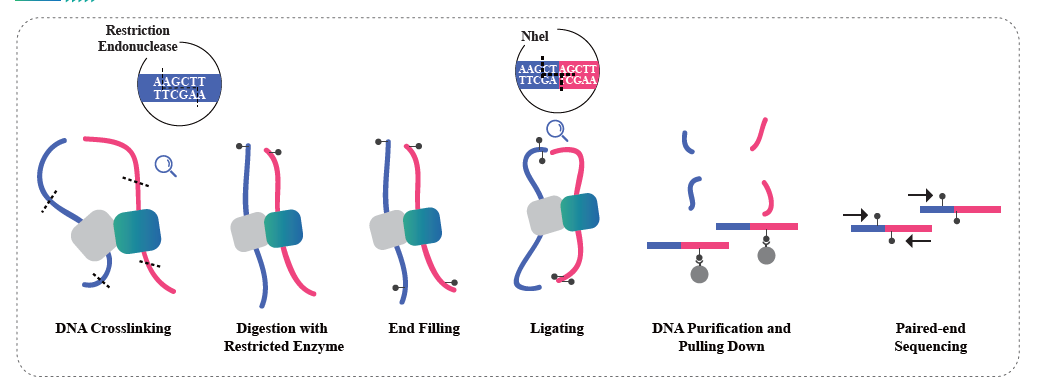
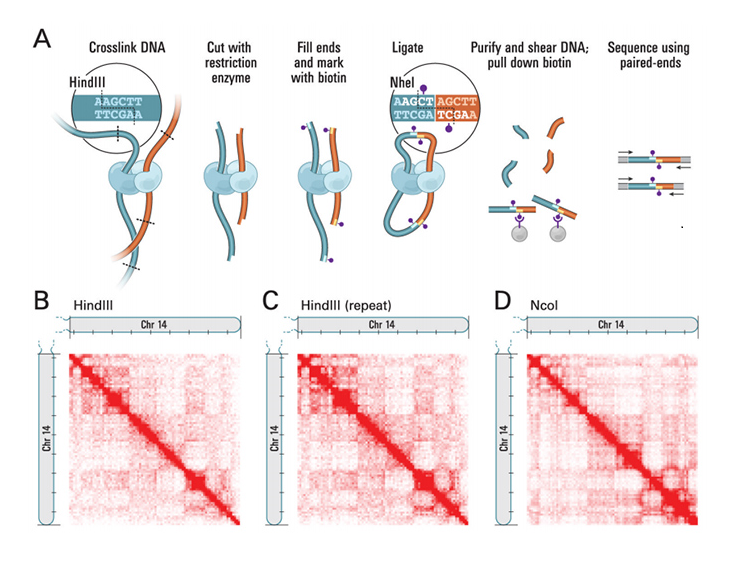
- Hi-C実験では、制限酵素による切断、そして付着末端の修復が行われ、その際にビオチンが付加されます。その後、相互作用を保持したまま、得られた平滑末端を環状化します。続いてDNAはストレプトアビジンビーズでプルダウンされ、その後のライブラリー調製のために精製されます。
【Hi-Cの特長】(fig.2)
- 遺伝子集団データの必要性を排除:Hi-Cは、コンティグのアンカリングに必要不可欠な情報を代替
- 高いマーカー密度:90%を超える高いコンティグアンカリング率を実現
- 豊富な専門知識と実績:BMKGeneは、1,000の異なる生物種に対する2,000例以上のHi-Cゲノムアセンブリの豊富な経験と、様々な特許を保有しています。200件を超える出版事例の累積インパクトファクターは、2,000を超えています。
- 熟練のバイオインフォマティクスチーム: Hi-C実験とデータ解析に関する特許と、著作権を持つ独自開発の視覚化データソフトウェアにより、手動でのブロック移動、反転、取り消し、やり直しが可能です。
- 包括的アノテーション:複数のデータベースを使用して、同定された変異を持つ遺伝子の機能的アノテーション付加、対応するエンリッチメント解析を行うことで、複数の研究プロジェクトに関する洞察を提供します。
- 解析完了後のサポート:プロジェクト完了後 3ヶ月のアフターサービス期間を設けています。この期間中、プロジェクトのフォローアップ、トラブルシューティングの支援、結果に関する疑問やご質問に対応致します。
サービス内容
ご送付頂いた DNA サンプルを用いて、品質チェック(QCチェック)から次世代シークエンスまで実施いたします。さらに、オプションでバイオインフォマティクス解析にも対応いたします。
【シークエンス内容】
| ライブラリー調製 |
シークエンス条件 |
推奨シークエンス深度 |
品質管理 |
| Hi-C ライブラリー |
illumina Novaseq PE150 |
100x |
Q30≧85% |
* 推奨シークエンス深度は、参考値です。
* QCチェックに合格したサンプルは、シークエンス量の保証対象となります。
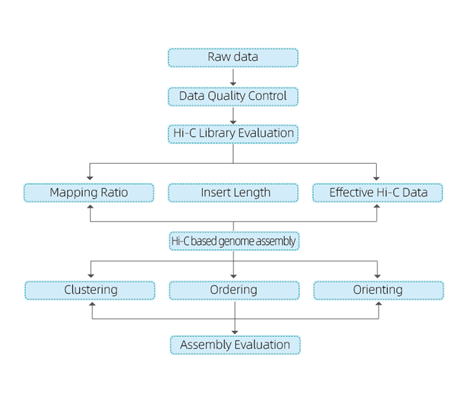
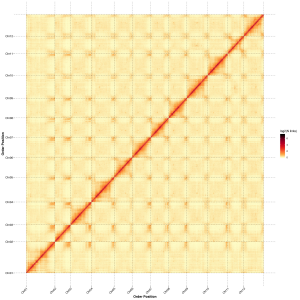
【データ解析内容】(
fig.3)
- データQC
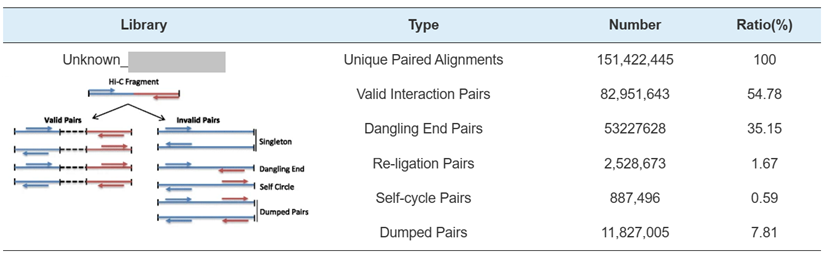
- Hi-C ライブラリー QC: 有効な Hi-C 相互作用の推定
- Hi-C アセンブリー: グループ内のコンティグのクラスタリング、各グループ内でのコンティグの順序付けおよびコンティグの方向の割り当て
- Hi-C 評価
* パッケージの解析内容は、業務提携先のパイプラインの変更・更新等により、変更される場合があります。
作業内容
- サンプルQCチェック
- ライブラリー作製
- シークエンス作業
- バイオインフォマティクス解析(有償オプション)